# 인공지능 기초 개념
안녕하세요 코드사기꾼입니다.
오늘은 Tensor에 대한 개념 정립을 하는 시간을 갖도록 하겠습니다. 인공지능 연구분야에서 가장 유명한 라이브러리인 TensorFlow를 정말 많은 사람들이 사용하고 있으면서도, 정작 그 의미에 대한 부분은 모르시는 분이 많은것 같아 포스팅을 해보기로 했습니다.
1. Tensor
텐서란 매우 수학적인 개념으로 데이터의 배열이라고 볼 수 있습니다. 텐서의 Rank는 간단히 말해서 몇 차원 배열인가를 의미합니다.
| RANK | TYPE | EXAMPLE |
| 0 | scalar | [1] |
| 1 | vector | [1,1] |
| 2 | matrix | [[1,1],[1,1]] |
| 3 | 3-tensor | [[[1,1],[1,1]],[[1,1],[1,1]],[[1,2],[2,1]]] |
| n | n-tensor |
스칼라는 일반적으로 존재하는 그냥 값(1개)입니다. 벡터는 스칼라가 여러개 모인것이며 차원이 높아질 수록 아래 차원의 것을 모아 놓은 배열인 것이라고 할 수 있습니다.
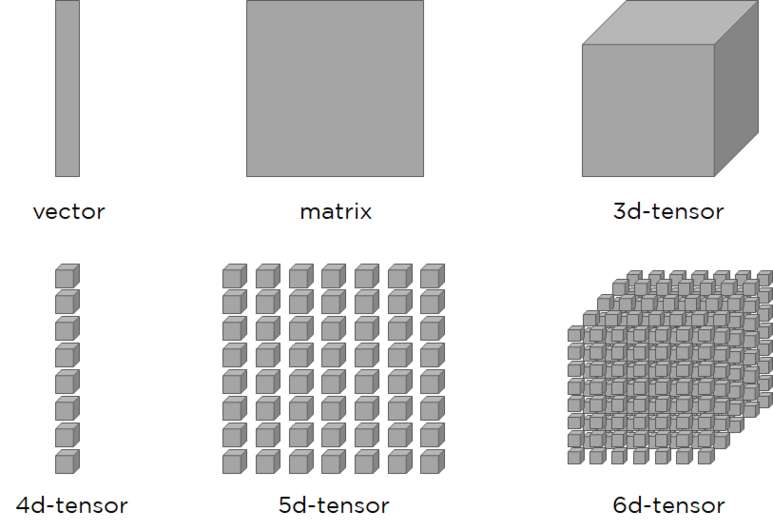
2. 예시
자연어 처리를 통하여 위의 내용에 대한 예제를 구성해 보도록 하겠습니다.
Hi King
Hi Queen
Hi Jack
이라는 Sentences가 존재할 때 one hot encoding으로 벡터를 나타내면 아래와 같습니다.
| WORD | INDEX | EXAMPLE |
| hi | 0 | [1,0,0,0] |
| king | 1 | [0,1,0,0] |
| queen | 2 | [0,0,1,0] |
| jack | 3 | [0,0,0,1] |
word를 vector로 나타내었으니 단어의 vector를 기반으로 문장을 matrix로 표현할 수 있을 것 같습니다.
| word | EXAMPLE |
| hi king | [[1,0,0,0],[0,1,0,0]] |
| hi queen | [[1,0,0,0],[0,0,1,0]] |
| hi jack | [[1,0,0,0],[0,0,0,1]] |
문장을 위처럼 matrix로 표현하였습니다. 하지만 저희는 신경망의 input으로 보통 말뭉치를 넣게 되는데요 말뭉치는 아래와 같이 표현할 수 있습니다.
hi king hi queen hi jack
[[[1,0,0,0], [0,1,0,0]],[[1,0,0,0], [0,0,1,0]],[[1,0,0,0], [0,0,1,0]]]
위의 말뭉치에서 각 word는 4차원으로 구성되어있습니다. 그리고 각 문자은 2개의 단어로 구성되어있습니다. 총 3개의 문장을 가지고 있으므로 위 모델은 (3,2,4)의 3차원 Tensor라고 볼 수 있는 것 입니다.
1. scalar
scalar에 해당하는 일반적인 숫자 한개를 넣어서 차원을 출력해 보았습니다.

대로 0 차원이 나왔습니다. 한개의 값만 존재하는 scalar는 0차원입니다.
그렇다면 vector는 어떨까요?
2. vector
vector값의 차원을 확인하기 위하여 [1,2,3,4,5]를 인풋으로 넣어봤습니다.
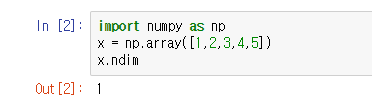
값이 1이 나왔습니다. 역시 vector는 1차원 데이터입니다.
3. matrix
matrix는 vector의 집합입니다. [[1,2,3],[4,5,6],[7,8,9]]를 인풋으로 넣었습니다.

예상에서 벗어나질 않네요 2차원이 나왔습니다. vector여러개가 모이면 2차원 데이터가 됩니다.
4. tensor
그렇다면 마지막으로 tensor입니다. matrix의 집합인 tensor는 당연히 3차원 부터 시작하니 최소 3이상의 수가 나올 것입니다. 저는 3d 텐서를 입력값으로 넣었으니 3이라는 수가 출력될 것입니다.

3이 잘 출력 된것을 볼 수 있습니다.
자 오늘은 tensor란 무엇인가로 시작하여 0차원 데이터 부터 고차원 데이터까지 명명법과 형태에 관하여 배워보았습니다. 오늘 배운것들을 정리하자면,
1. Tensor는 배열의 집합이다.
2. 차원의 수는 Rank와 같은말이다.
3. 배열의 차원에따라 불리는 이름이 달라진다.
'Dev > Artificial Intelligence' 카테고리의 다른 글
| [인공지능 개념] 지도/비지도학습과 강화학습 (2) | 2019.04.08 |
|---|








